我表示是跟着黄伟牛混的.. 他写的报告难以称作报告.. 题目一抄写两句话代码一贴万事, 自己琢磨了好久, 记录一下, 我记性不好喜欢写的详细一点以后自己可以查.. (拓展阅读: 刘未鹏牛的<为什么你应该(从现在开始就)写博客> )
快放假了, ACM + GRE 加油, 不拼命的下场只有一个, 平庸.. 哞
第一问 total number of symbols in BC(n,k,m) 比较容易, 简单DP
dp[n][k][m]=∑dp[n-i][k-1][m] , i∈[1,m]
第二问 yzhw口口声声“经典的逐位确定方法”..
也就是说, 我们来看 “1111010”(从0位到6位), 简单的讲从高位(0)到低位(6)每一位如果有1, 那么就看, 如果这一位是0, (继承前面的高位后) 低位能形成多少种组合, 把这个组合数加到rank中.
流程是 1[0xxxxx]能有多少组合 即求0xxxxx符合k-1和m的组合(直接用前面求出的dp数组即可, 虽然前面求的是1xxxxx, 但是和0xxxxx数量是一样的), 然后11[0xxxx]能有多少种, 遇到0跳过, 最后看11110[0x]
但是这样并不完全缜密, 我们考虑”10011000″的情况, 按上面的算法进行到第3位的时候, 100[0xxxx], 这个0xxxx是可能产生00011这种组合的, 而放入原文就变成了10000011, 0的长度就超过了. 所以我们想出来的办法是把 0-1 (不包括1到0) 交界处的那个1单独考虑, 看前面有多少位0然后详细说明. 比如100[0xxxx], xxxx只能是以1开头的, 10[0xxx], xxx只能是1xx或者01x, (11x到哪去了? 11x不是在这里的 [特殊情况] 内考虑的, 好好想一下.. 没法讲的太清楚)
代码如下, 写的时候很有自己的想法, 多推敲推敲最后的产品和yzhw的也八九不离十了.. 这个代码还是很精简很漂亮的
[cpp]
#include <stdio.h>
#include <string.h>
#include <algorithm>
int main() {
int dp[34][34][34];
memset(dp,0,sizeof(dp));
//DP
for(int m=1;m<=33;m++) {
for(int i=1;i<=m;i++)
dp[i][1][m]=1;
for(int k=1;k<33;k++)
for(int n=k;n<33;n++) {
if(!dp[n][k][m])
break;
for(int i=1;i<=m;i++) {
if(n+i>33)
break;
dp[n+i][k+1][m]+=dp[n][k][m];
}
}
}
int n,k,m;
scanf("%d%d%d",&n,&k,&m);
printf("%d\n",dp[n][k][m]);
int N;
scanf("%d",&N);
while(N–) {
char a[34];
scanf("%s",a);
char color=’1′;
int rank=0;
int kRemain=k;
int head=0;
for(int p=0;a[p]!=’\0’;p++) {
if(color==a[p])
continue;
if(color==’1′) {
color=’0′;
kRemain–;
for(int i=head+1;i<p;i++)
rank+=dp[n-i][kRemain][m];
}
else {
color=’1′;
kRemain–;
for(int i=std::min(n-1,head+m);i>p;i–)
rank+=dp[n-i][kRemain][m];
}
head=p;
}
printf("%d\n",rank);
}
return 0;
}
[/cpp]

 generates the Beatty sequence
generates the Beatty sequence
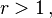 then
then  is also a positive irrational number. They naturally satisfy
is also a positive irrational number. They naturally satisfy
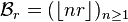 and
and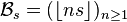
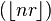 , known as the lower Wythoff sequence, is
, known as the lower Wythoff sequence, is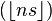 , the upper Wythoff sequence, is
, the upper Wythoff sequence, is